%20--%3e%3csvg%20version='1.0'%20id='Layer_1'%20xmlns:sodipodi='http://sodipodi.sourceforge.net/DTD/sodipodi-0.dtd'%20xmlns:krita='http://krita.org/namespaces/svg/krita'%20xmlns='http://www.w3.org/2000/svg'%20xmlns:xlink='http://www.w3.org/1999/xlink'%20x='0px'%20y='0px'%20viewBox='0%200%20188.06%20188.06'%20style='enable-background:new%200%200%20188.06%20188.06;'%20xml:space='preserve'%3e%3cstyle%20type='text/css'%3e%20.st0{fill-rule:evenodd;clip-rule:evenodd;fill:%23FFFFFF;stroke:%230E3147;stroke-width:3.6;stroke-linecap:square;stroke-linejoin:bevel;}%20.st1{fill-rule:evenodd;clip-rule:evenodd;fill:%23FFFFFF;stroke:%230E3147;stroke-width:4.32;stroke-linecap:square;stroke-linejoin:round;}%20.st2{fill-rule:evenodd;clip-rule:evenodd;fill:%230E3147;stroke:%230E3147;stroke-width:0.72;stroke-linecap:square;stroke-linejoin:round;}%20.st3{fill-rule:evenodd;clip-rule:evenodd;fill:%230E3147;stroke:%230E3147;stroke-width:1.1808;stroke-linecap:square;stroke-linejoin:bevel;}%20.st4{fill:none;stroke:%230E3147;stroke-width:2.6568;stroke-linecap:square;stroke-miterlimit:2;}%20.st5{fill-rule:evenodd;clip-rule:evenodd;fill:%2386C7F3;}%20.st6{fill:none;stroke:%230E3147;stroke-width:1.44;stroke-linecap:square;stroke-miterlimit:2;}%20%3c/style%3e%3cpath%20id='shape0'%20sodipodi:nodetypes='ccccc'%20class='st0'%20d='M75.38,10.46L42.62,50.78l30.24,47.88l55.8-68.04L75.38,10.46z'/%3e%3cpath%20id='shape1'%20sodipodi:nodetypes='cccccccccc'%20class='st1'%20d='M64.65,92.18L55.54,106l32.02,30.67l-15.86,19.15L3.74,94.07%20v58.36l34.29,31.9h68.4l35.1-40.14L64.65,92.18z'/%3e%3cpath%20id='shape2'%20sodipodi:nodetypes='ccccccccccccccccccccccccc'%20class='st2'%20d='M129,104.47l5.69,4.71l9.39,28.87l14.75-1.21%20l-11,12.16l-23.85,2.53L48.49,85.24l-4.51-16.55L31.42,54l-3.91-37.91l44.18,38.75l0.68,19.27l46.76,37.71L129,104.47%20M147.38,76.97%20l11.34,10.15h22.31l3.23,14.82l21.18-31.18L82.58-34.27L46.22-10.24L90.5,26.62l18.09-0.88l44.5,40.34L147.38,76.97'/%3e%3cpath%20id='shape3'%20sodipodi:nodetypes='ccccc'%20class='st3'%20d='M37.76,55.46L15.98,83.72l41.04,34.02L70.88,98.3L37.76,55.46z'/%3e%3cpath%20id='shape4'%20sodipodi:nodetypes='cc'%20class='st4'%20d='M112.51,49.03L98.29,35.98'/%3e%3cpath%20id='shape01'%20sodipodi:nodetypes='cc'%20class='st4'%20d='M94.13,72.11L79.91,59.06'/%3e%3cpath%20id='shape02'%20sodipodi:nodetypes='cc'%20class='st4'%20d='M103.71,60.73l-9.63-9'/%3e%3cpath%20id='shape03'%20sodipodi:nodetypes='cc'%20class='st4'%20d='M123.83,163.5l-12.78-11.93'/%3e%3cpath%20id='shape011'%20sodipodi:nodetypes='cc'%20class='st4'%20d='M108.02,182.76L93.8,169.71'/%3e%3cpath%20id='shape021'%20sodipodi:nodetypes='cc'%20class='st4'%20d='M117.06,172.91l-9.63-9'/%3e%3cpath%20id='shape04'%20sodipodi:nodetypes='cccccc'%20class='st5'%20d='M133.45,91.42l13.3,41.98l17.93-1.67l16.41-23.34l-3.51-16.97H133.45%20z'/%3e%3cpath%20id='shape5'%20sodipodi:nodetypes='cccccc'%20class='st5'%20d='M133.45,91.42l13.3,41.98l17.93-1.67l16.41-23.34l-3.51-16.97H133.45z%20'/%3e%3cpath%20id='shape6'%20sodipodi:nodetypes='cc'%20class='st6'%20d='M174.92,95.6l-26.6,35.37'/%3e%3cpath%20id='shape7'%20sodipodi:nodetypes='ccccc'%20class='st6'%20d='M174.79,114.16l-5.51-10.48l-32.38-9.51l18.11,27.69l11.34,3.24'/%3e%3c/svg%3e)
STORYGOLD
foundation model for parametric CAD
We're building a 3D reasoning model
01 Vibecoding for CAD design
StoryGold is training a foundation model that understands and generates the 3D world through parametric CAD. Unlike existing AI models that produce static meshes or images, our model generates fully editable, production-ready CAD files.

02 Training on terabytes of data
We're building the world's largest parametric CAD dataset. Focusing on parametric CAD enables our model to preserve engineering intent (dimensions, constraints, relationships) that are essential for downstream editing, simulation, and manufacturing.

03 Building general intelligence
True general intelligence must understand the physical world. In Jennifer's previous role at Waymo, she built large-scale deep learning models to navigate the real world. It's clear to us that 3D reasoning is required to truly build general intelligence.

We've got lots of experience building foundation models at Waymo and Google
LoRA Fine-Tuning for Vision-Language Models
LoRA is touted as being as effective as full-fine tuning, but is it true? LoRA fine-tuning performs significantly worse than full fine-tuning for vision-language models learning spatial reasoning on CAD data, suggesting LoRA's low-rank assumption fails when teaching models genuinely new capabilities far from their pre-training distribution. This potentially means that effective CAD model training requires full fine-tuning with 100,000+ examples and substantial GPU resources, rather than the more efficient LoRA approach that works well for tasks closer to the model's existing knowledge.

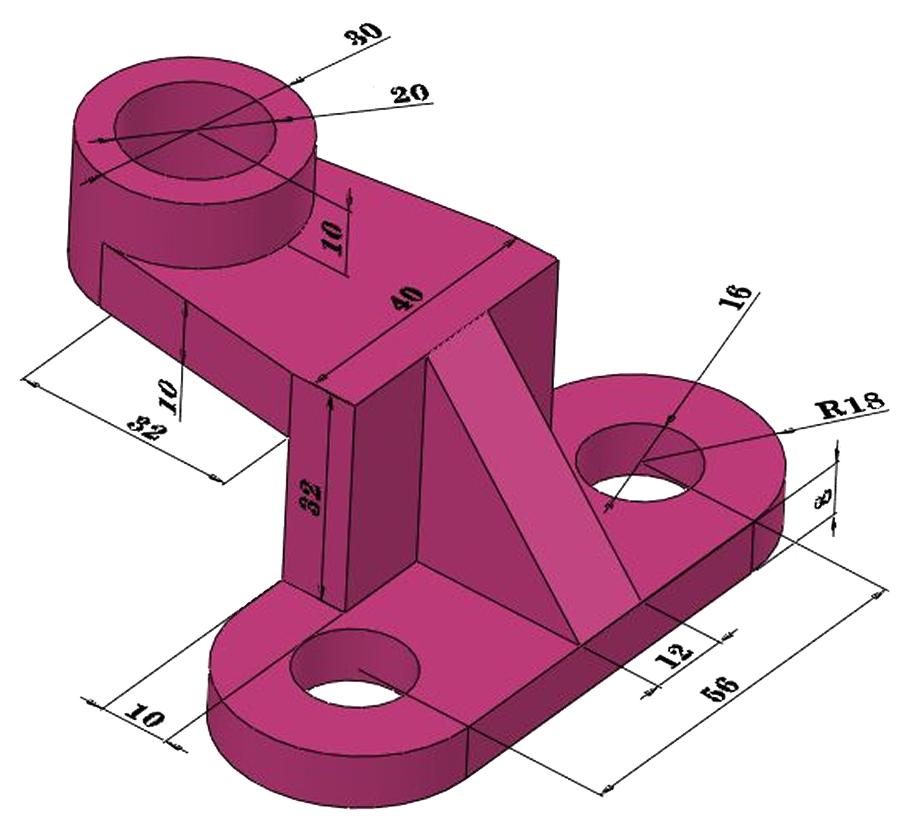
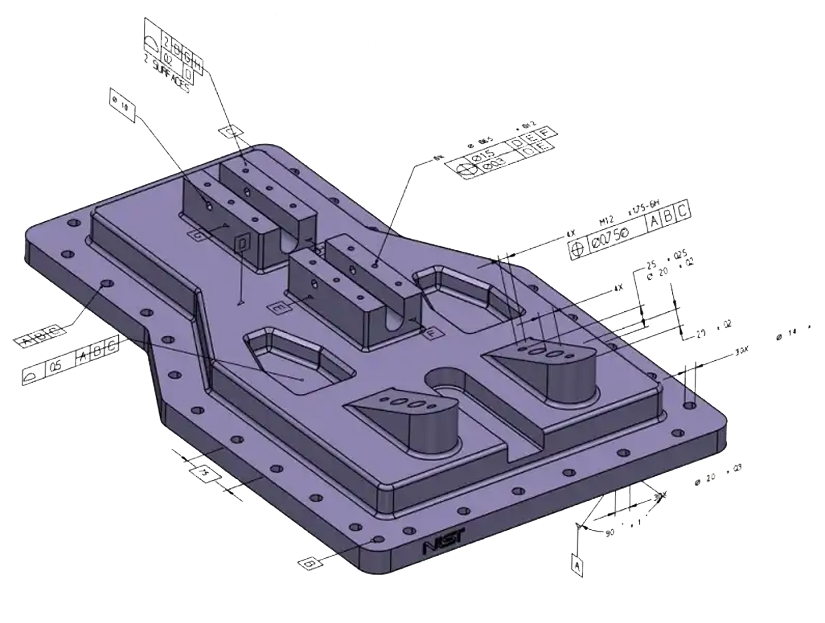
How good is GPT-5 at 3D?
GPT-5 can write syntactically perfect code with the right prompting techniques, but when it comes to actually understanding 3D space and geometry, even OpenAI's most advanced model falls dramatically short of specialized fine-tuned systems. This reveals a critical insight: you can't teach a model to truly "see" and reason about 3D space; some capabilities require fundamentally different training approaches that go far beyond clever prompting. In this post, we present an empirical analysis on GPT-5's performance on parametric CAD generation.
We believe that building AGI requires intelligence that can understand the 3D world