%20--%3e%3csvg%20version='1.0'%20id='Layer_1'%20xmlns:sodipodi='http://sodipodi.sourceforge.net/DTD/sodipodi-0.dtd'%20xmlns:krita='http://krita.org/namespaces/svg/krita'%20xmlns='http://www.w3.org/2000/svg'%20xmlns:xlink='http://www.w3.org/1999/xlink'%20x='0px'%20y='0px'%20viewBox='0%200%20188.06%20188.06'%20style='enable-background:new%200%200%20188.06%20188.06;'%20xml:space='preserve'%3e%3cstyle%20type='text/css'%3e%20.st0{fill-rule:evenodd;clip-rule:evenodd;fill:%23FFFFFF;stroke:%230E3147;stroke-width:3.6;stroke-linecap:square;stroke-linejoin:bevel;}%20.st1{fill-rule:evenodd;clip-rule:evenodd;fill:%23FFFFFF;stroke:%230E3147;stroke-width:4.32;stroke-linecap:square;stroke-linejoin:round;}%20.st2{fill-rule:evenodd;clip-rule:evenodd;fill:%230E3147;stroke:%230E3147;stroke-width:0.72;stroke-linecap:square;stroke-linejoin:round;}%20.st3{fill-rule:evenodd;clip-rule:evenodd;fill:%230E3147;stroke:%230E3147;stroke-width:1.1808;stroke-linecap:square;stroke-linejoin:bevel;}%20.st4{fill:none;stroke:%230E3147;stroke-width:2.6568;stroke-linecap:square;stroke-miterlimit:2;}%20.st5{fill-rule:evenodd;clip-rule:evenodd;fill:%2386C7F3;}%20.st6{fill:none;stroke:%230E3147;stroke-width:1.44;stroke-linecap:square;stroke-miterlimit:2;}%20%3c/style%3e%3cpath%20id='shape0'%20sodipodi:nodetypes='ccccc'%20class='st0'%20d='M75.38,10.46L42.62,50.78l30.24,47.88l55.8-68.04L75.38,10.46z'/%3e%3cpath%20id='shape1'%20sodipodi:nodetypes='cccccccccc'%20class='st1'%20d='M64.65,92.18L55.54,106l32.02,30.67l-15.86,19.15L3.74,94.07%20v58.36l34.29,31.9h68.4l35.1-40.14L64.65,92.18z'/%3e%3cpath%20id='shape2'%20sodipodi:nodetypes='ccccccccccccccccccccccccc'%20class='st2'%20d='M129,104.47l5.69,4.71l9.39,28.87l14.75-1.21%20l-11,12.16l-23.85,2.53L48.49,85.24l-4.51-16.55L31.42,54l-3.91-37.91l44.18,38.75l0.68,19.27l46.76,37.71L129,104.47%20M147.38,76.97%20l11.34,10.15h22.31l3.23,14.82l21.18-31.18L82.58-34.27L46.22-10.24L90.5,26.62l18.09-0.88l44.5,40.34L147.38,76.97'/%3e%3cpath%20id='shape3'%20sodipodi:nodetypes='ccccc'%20class='st3'%20d='M37.76,55.46L15.98,83.72l41.04,34.02L70.88,98.3L37.76,55.46z'/%3e%3cpath%20id='shape4'%20sodipodi:nodetypes='cc'%20class='st4'%20d='M112.51,49.03L98.29,35.98'/%3e%3cpath%20id='shape01'%20sodipodi:nodetypes='cc'%20class='st4'%20d='M94.13,72.11L79.91,59.06'/%3e%3cpath%20id='shape02'%20sodipodi:nodetypes='cc'%20class='st4'%20d='M103.71,60.73l-9.63-9'/%3e%3cpath%20id='shape03'%20sodipodi:nodetypes='cc'%20class='st4'%20d='M123.83,163.5l-12.78-11.93'/%3e%3cpath%20id='shape011'%20sodipodi:nodetypes='cc'%20class='st4'%20d='M108.02,182.76L93.8,169.71'/%3e%3cpath%20id='shape021'%20sodipodi:nodetypes='cc'%20class='st4'%20d='M117.06,172.91l-9.63-9'/%3e%3cpath%20id='shape04'%20sodipodi:nodetypes='cccccc'%20class='st5'%20d='M133.45,91.42l13.3,41.98l17.93-1.67l16.41-23.34l-3.51-16.97H133.45%20z'/%3e%3cpath%20id='shape5'%20sodipodi:nodetypes='cccccc'%20class='st5'%20d='M133.45,91.42l13.3,41.98l17.93-1.67l16.41-23.34l-3.51-16.97H133.45z%20'/%3e%3cpath%20id='shape6'%20sodipodi:nodetypes='cc'%20class='st6'%20d='M174.92,95.6l-26.6,35.37'/%3e%3cpath%20id='shape7'%20sodipodi:nodetypes='ccccc'%20class='st6'%20d='M174.79,114.16l-5.51-10.48l-32.38-9.51l18.11,27.69l11.34,3.24'/%3e%3c/svg%3e)
We conducted a quick and dirty evaluation of GPT-5, OpenAI's latest frontier model, and its capabilities on parametric CAD code generation. While GPT-5 represents significant progress toward more general AI systems, our experiments reveal limitations in its ability to perform spatial reasoning tasks, similar to its predecessor, GPT-4. We tried some simple techniques like retrieval-augmented generation (RAG) on the CadQuery API documentation and few-shot learning.
Experimental Design
We evaluated multiple configurations of GPT models on our parametric CAD generation benchmark:
- GPT-5 (baseline): Zero-shot generation
- GPT-5 + Few-shot: Prompted with 3-4 high-quality example image-code pairs
- GPT-5 + RAG: Augmented with retrieval from CadQuery API documentation
- GPT-5 + RAG + Few-shot: Combined approach using both techniques
- GPT-4 (baseline): Previous generation model for comparison
- BELLA v1.0 (13B and 34B): Our fine-tuned models for reference
An example of a few-shot prompt:
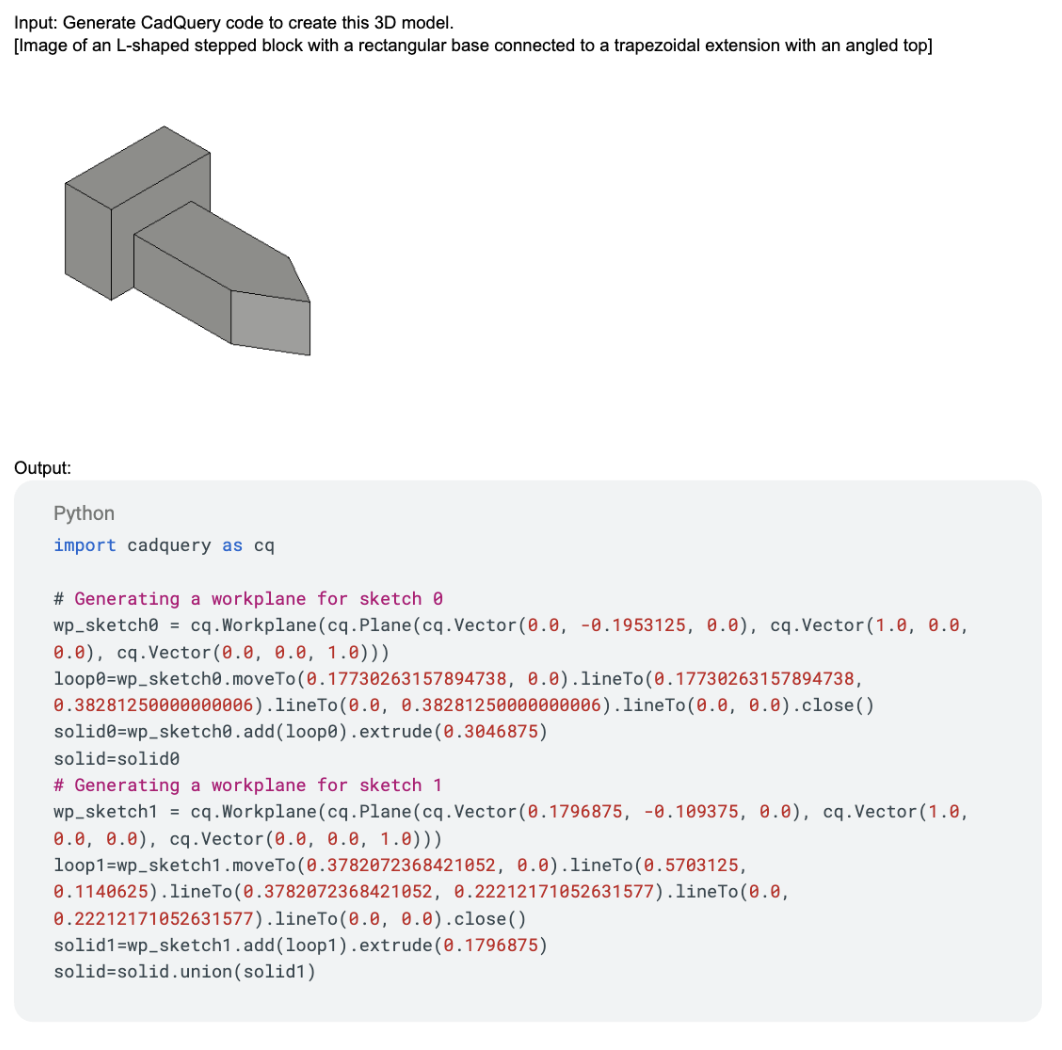
We measured two key metrics:
- Code Validity Rate: The percentage of generated Python CadQuery code samples that compile and produce a valid solid without errors
- Intersection-over-Union (IoU): Geometric accuracy of successfully compiled outputs, measured against ground truth models (scale from 0 to 1.0, where 1.0 represents perfect geometric agreement)
Results
| Model | Validity % | IoU Score |
|---|---|---|
| BELLA v1.0 34B | 99% | 0.75 |
| BELLA v1.0 13B | 98% | 0.73 |
| GPT-5 + RAG + Few-shot | 98% | 0.49 |
| GPT-5 + RAG | 92% | 0.48 |
| GPT-5 + Few-shot | 90% | 0.47 |
| GPT-5 | 89% | 0.43 |
| GPT-4 | 93% | 0.43 |
The combination of RAG and few-shot learning dramatically improved GPT-5's code validity rate from 89% to 98%. Basically, knowing about the CadQuery API and a few examples of how to use it produced an 82% reduction in syntax and API errors (from 11% failures to 2% failures). In some ways, this is not surprising, as GPT-5 is exceptionally good at coding tasks, as shown by the myriad of codegen tools that are widely adopted.
Despite the substantial improvement in code validity, geometric accuracy remained largely unchanged. GPT-5's IoU score improved only marginally from 0.43 (baseline) to 0.49 (RAG + few-shot), whereas BELLA v1.0 (fine-tuned using a CadQuery dataset) sits at 0.75 IoU.
What does this mean? Well, generating syntactically correct code is fundamentally different from generating three-dimensional, geometrically accurate code! RAG and few-shot learning can teach a model correct API usage patterns, but they cannot teach deep spatial awareness!
Analysis
Most likely, trying to teach a model something that deviates far away from its pre-training data -- like spatial reasoning -- requires expensive fine-tuning or even specialized architecture trained from scratch. It's also possible that LLaVA's vision-language architecture may be better suited for geometric tasks than GPT's text-centric architecture, even before fine-tuning anything.
While GPT-5 represents impressive progress in general AI capabilities, our experiments demonstrate that frontier-scale models augmented with RAG and few-shot learning still cannot match specialized, fine-tuned models on 3D spatial reasoning tasks.